Medical Insurance Cost Prediction
- The primary objective of this project was to employ regression models to predict the cost of medical insurance and gain valuable insights into its influencing factors.
- The dataset, sourced from Kaggle, underwent minimal data cleaning and formatting procedures to ensure its suitability for analysis.
- The selection of Linear Regression, Decision Tree, and Random Forest models was based on their adeptness in handling both categorical and continuous data types.
- Upon evaluation, the Random Forest model emerged as the top performer, exhibiting the lowest Mean Squared Error (MSE) and the highest R-squared value among the three models.
- Notably, smoking emerged as the most significant determinant of medical insurance cost, followed by BMI and age, according to the analysis.
Resources
Python Version: 3.10.12
Packages: NumPy, Pandas, Matplotlib, Seaborn
Data Collection
Dataset was on Kaggle under the title Medical Insurance Cost Prediction.
EDA
As can be shown below there is a severe under representation of samples with charges of over $20,000. This is reflective of what we expect to find in the real world but some outcome imbalance is likely to occur.

Intuition dictates that many of the factors considered in medical insurance cost would be linearly correlated to the cost. One would have to perform linearity checks on each of the variables, one of which, age, is shown below.

The fact that the Linearity Check plot exhibits three quasi-linear patterns that run parallel to one another suggests that age is inexorably intertwined with one or more variables. It could also be posited that age will likely serve as some sort of sub-classifier into a ‘tier of cost’. Decision Tree or Random Forest models are better equipped for handling such variables.
The other predictors suffered from skewed data but generally exhibibted potential for linear relationships with the response variable. For further insights and graphical representations, the EDA notebook is found here.
Model Building
Linear Regression, Decision Tree, and Random Forest were the three model candidates due to their ability to model both categorical and continuous data. As speculated in the Age variable exploration in the EDA, Decision Tree and Random Forest models performed significantly better than Linear Regression – each achieving R-squared values over 90%, while the Linear Regression model was at 73%.
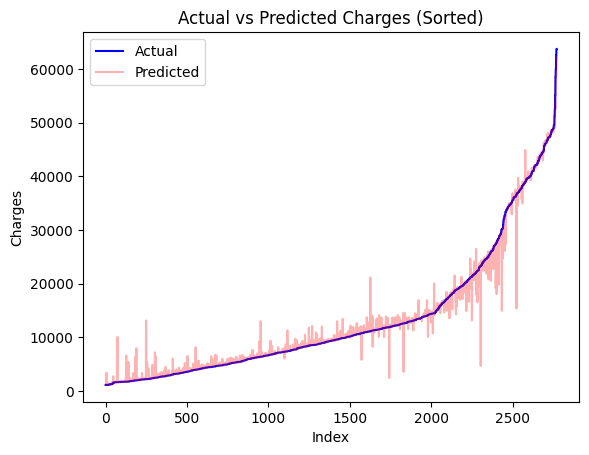
Below is a plot of the dataset, sorted, and the respective Random Forest prediciton. The notebook for the model builing and evalution can be found here.
Implications
- Smoking Dominates Costs: Smoking status is the most critical factor, contributing 62.6% to insurance cost prediction.
- BMI Matters: BMI is the second most important predictor, influencing 20.97% of insurance cost variation.
- Age Counts: Age is significant, contributing 12.53% to insurance cost prediction.
- Other Factors Are Less Impactful: Number of children, sex, and region have limited impact, collectively contributing 4.9% to prediction.
GitHub Repository for “Medical Insurance Cost Prediction” Project
Back to Data Analytics Portfolio